A virtual cluster is based on the principles of abstraction and advanced orchestration, hence creating a flexible computing environment based on a resource pool of physical servers. Its functionality may be divided into three fundamental layers which are the physical infrastructure, the virtualization layer and the orchestration and management plane.
The basic building block is the physical cluster which is Efficiency and agility are not just beneficial in the modern digital enterprise architecture, but living. Cloud computing has taken the final shape as the pillar of this milieu, as it allows organizations to overcome the boundaries of hardware equipment. However, what is really sophisticated about the cloud is not its large pools of resources but rather the smart, dynamically evolving systems that run on the cloud. The two concepts that are highly intertwined at the center of this operational excellence are virtual cluster and resource management in cloud computing. These are not fringe benefits; they are the core mechanisms that make dynamically responding, resilient and economically streamlined utility out of the stature infrastructure.
This analysis goes beyond the high abstraction level to investigate the operating base of the cloud. We will disassemble the way virtual clusters abstract and consolidate real assets and shed light on the complex methods of doing so like live migration. Understanding this synergy is critical to every technical leader or architect who is tasked with the responsibility of building scalable, reliable and cost effective systems in the modern competitive environment.
This manual attempts to debunk these ideas. We shall discuss the definition of virtual clusters, the difference between them and their physical equivalents, and what advanced methods, like live migration, cloud providers use to handle them with amazing effectiveness.
The Foundation- Physical to Virtual Clusters
To understand the virtual, we must first understand the physical.
What is a Physical Cluster?
A physical cluster is a group of physically networked physical computers (also known as nodes) that are provided to work as a single, cohesive computing resource. These nodes are connected to each other through a high speed network and they are often contained in the same rack or data center. They are seen as one system that aims at addressing issues that are too big or too complicated to be resolved by an individual machine.
- Use Case: Classical HPC of scientific simulations, weather modelling and genomic sequencing.
- Key Trait: Dedicated, fixed resources. You own and manage the specific hardware.
The Restriction of Physical Clusters:
Physical clusters are rigid in nature. The expensive servers are not in use when one project is being terminated and when another project is not initiated. In case a project needs more power than expected, then new hardware has to be bought and installed which is not only inefficient but time consuming as well. This ineffectiveness is the opposite of the philosophy of cloud computing on demand.
What is Virtual Cluster?
Virtual cluster Virtual machines (VMs) or containers are deployed on top of a set of physical cluster nodes and operations as a single logical unit. The difference is abstraction; the virtual cluster has no idea about the physical servers on which it actually runs.
A hypervisor, like VMware ESXi or Linux KVM, or a container orchestrator, like Kubernetes, allows this abstraction. These systems divide the physical resources, which are CPUs, memory, and storage and package these resources into isolated virtual units.
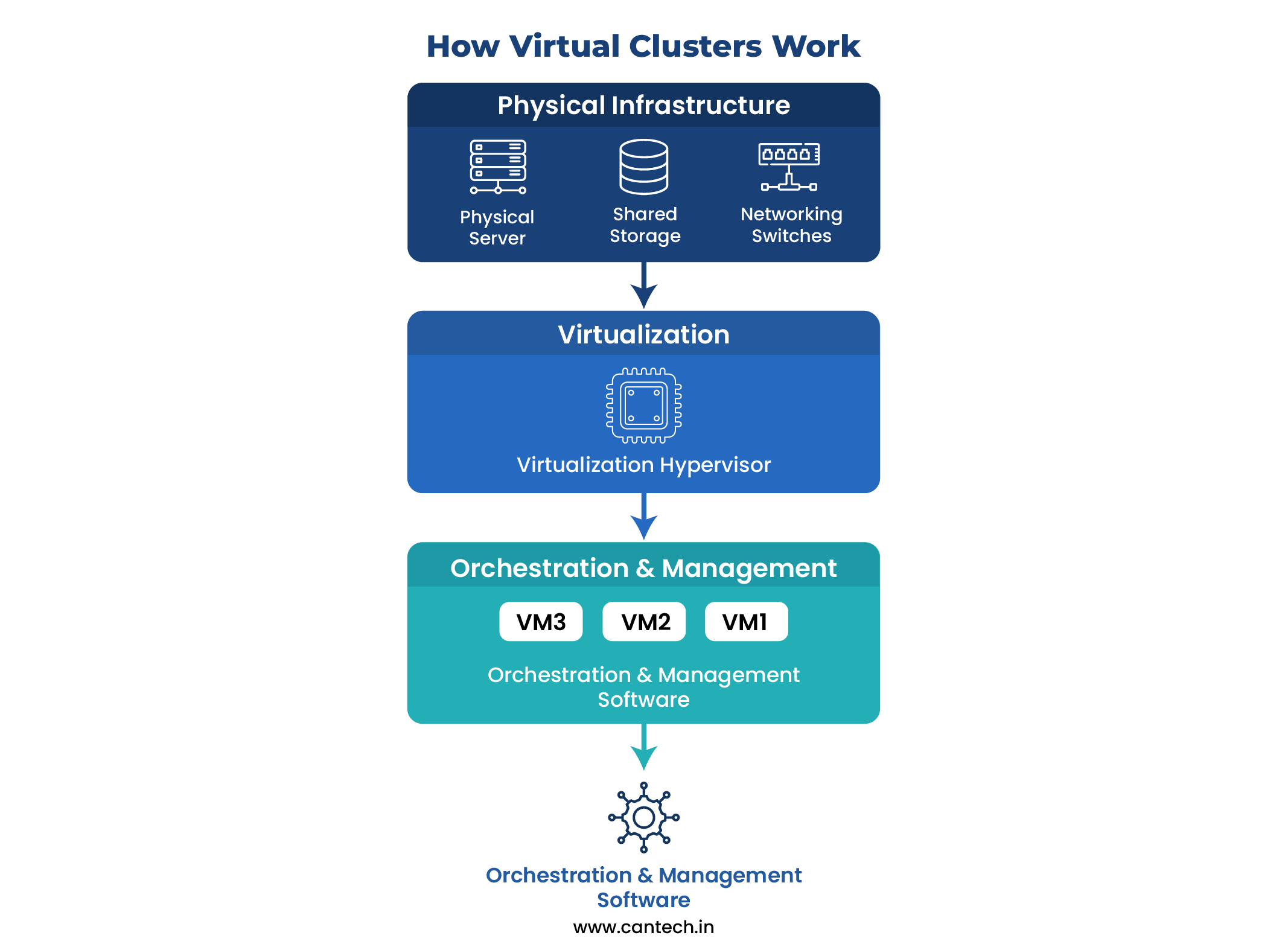
a set of physically linked physical servers (nodes), storage and switches of networks. This hardware pool is what offers the raw compute, memory and storage power. More importantly, these resources are not committed but are being combined so as to be shared by several virtual clusters.
The second layer is the virtualization hypervisor which is installed in every physical server. The main priority of the hypervisor is to separate the operating system and applications out of the hardware. It divides the physical resources of a server such as its CPUs, RAM and disk into various isolated and secure virtual machines (VMs) or containers. Each VM in the virtual cluster thinks that it is in its own dedicated hardware and oblivious that it shares the physical node with other objects. This abstraction is the basic enabler which enables the presence of various autonomous virtual clusters on the same physical infrastructure.
The third and advanced level entails the orchestration and management software, including Kubernetes of containers or VMware vCenter of VMs. This is the brain of operation. The administrator defines the required state of the virtual cluster- i.e. ten web server VMs, two database VMs, and a load balancer. To actualize that state is the work of the orchestrator. It automatically decides which physical host will be best to start every VM on in regard to its current load, available resources, and affinity rules. It checks the health of all VMs constantly.
When a physical server crashes, the orchestrator identifies the failure and automatically recovers the affected VMs on healthy nodes in the pool and thus maintains the virtual cluster to be available and resilient. Such a lifecycle management consisting of provisioning, placement, healing, and scaling is what makes a stagnant set of VMs a dynamic, self-healing virtual cluster.
Nervous System- Resource Management in Cloud Computing
Resource management is the advanced electronic control unit that makes the engine run smoothly in case virtual clusters are its representation. It includes the policies and mechanisms which are used to allocate the underlying physical resources- CPU, memory, storage, network to the virtual entities.
Resource management aims at meeting the conflicting needs of:
- Users of clouds, who need performance, reliability and speed in accessing resources.
- Cloud providers, which seek to increase utilization, energy efficiency and profit.
Key Techniques of Resource Management
Provisioning: Scheduling
This is about placing the right workload on the right server at the right time.
Static Provisioning
The resources are distributed beforehand and based on the anticipated needs. Although this method is easy, it can lead to over-provisioning, which causes waste, and under-provisioning, which reduces performance.
Dynamic Provisioning
One of the remarkable features of cloud environments lies in the possibilities of dynamically provisioning resources as per the real-time demand. As traffic to a site grows, the cloud platform automatically adds more web-server virtual machines to handle the traffic. This is the nature of elasticity as a dynamic allocation.
Load Balancing
Load balancing spreads network traffic and computing workloads between several nodes in a virtual cluster uniformly. The practice will avoid having a single virtual machine as a bottleneck that would limit throughput and increase response times. The load balancer acts as a referee and sends a request to a server that is least busy.
Performance Isolation
Isolation is necessary in a shared cluster environment, where a single physical hardware is shared among multiple virtual clusters of distinct customers or departments. It ensures that a noisy neighbor (a virtual machine that suddenly slurps large portions of CPU resources) does not affect the performance of the other virtual machines. This isolation is imposed by the hypervisor using resource limits and quotas.
Resource Monitoring and Forecasting
Cloud computing platforms use extensive telemetry and monitoring to determine the wellbeing and performance of all physical and virtual elements. The resultant data is fed into prediction algorithms that predict the future demands thus allowing the system to preemptively reassign resources before the event of a possible bottleneck occurs.
Live Migration and Its Components
Here cloud resource management becomes more than just an intelligent process, it takes on the quality of magic. Live Migration, which is considered as the best of current resource management, involves a transfer of a running VM in this case between physical hosts without any service disruption.
What is So Essential about Live Migration?
Proactive Maintenance: When a physical server needs repairing of hardware or updating firmware, the cloud provider has an option to migrate all virtual machines on such a server before carrying out the maintenance and later back them after it has been done. The strategy removes service unavailability and offers a seamless experience to the customers.
- Load Rebalancing: In case of overloading of a physical host, then the system can automatically relocate the chosen virtual machines to the less loaded host, thus reestablishing normal performance of all the affected services.
- Energy Conservation (Server Consolidation): When the demand is low, virtual machines can be shifted off a group of physical servers, allowing the idle physical servers to be shut down and hence allowing very high energy savings.
- Live Migration: It is a complicated process and involves the smooth movement of three fundamental elements:
- Memory Migration: This aspect is the most difficult one since all the operation state of the virtual machine is stored in its random-access memory.
Pre-Copy Interactive Approach
The hypervisor performs the transfer, in which all the virtual machine memory pages are to be migrated into the target host though the virtual machine continues to run on the source host.
- In this migration, the running virtual machine can alter some pages of the memory; these pages are considered pages.
The hypervisor then copies these pages a number of times.
- With repeated cycles of this process, the pages that are left behind shrink to a small size, and the virtual machine can briefly stop.
- The last batch of pages is then copied and the virtual machine is then immediately restarted on the target host.
- The delay is often so short, in milliseconds, that network connections, including TCP sessions, do not get dead and the user does not feel any delay.
- Network Migration: This is necessary to ensure continuous connectivity and therefore the network state must remain constant.
- The IP and MAC address of the virtual machine is moved to the new host.
- Such a hypervisor typically works together with the network switches to update forwarding tables so that the network packets can be immediately redirected to the new physical address of the virtual machine.
- The techniques it uses to broadcast include ARP (Address Resolution Protocol) which is used to update the network about the relocation of the virtual machine to avoid loss of packets.
Storage Migration
It is related to the disk of the virtual machine.
- Easiest Scenario (Shared Storage): In the cases when the source and destination host is connected to a central SAN (Storage Area Network), there is no transfer of the disk files of the virtual machine, instead both the hosts have access to the same files. The compute resources are only migrated, including CPU and memory.
- Complex Scenario (Non-Shared Storage): If hosts use local storage, the disk data must also be copied. This can be done beforehand (“cold” storage migration) or, in more advanced systems, live in parallel with the memory migration, though it’s slower and more resource-intensive.
Architectural Models -Shared Clusters and P2P Networks
The physical infrastructure architecture has quite a significant impact on the realization of resource management.
The Centralized Shared Cluster Model
This paradigm is the most common one in the commercial cloud services market; AWS, Azure, and Google Cloud.
Architecture: A large, centralized cluster of physical servers is managed by a master server or a set of manager servers. This centralized control has a complete picture of all the resources and makes any decisions concerning scheduling and migration.
Pros:
- High Efficiency: The central scheduler can determine optimal placement decisions that can optimize resource utilization in the entire pool.
- Simplified Management: There is only one locus of control over policies, security and updates.
- Strong Guarantees: The model suits quite well in the delivery of Service Level Agreements (SLAs).
Cons:
- Single Point of Failure: This poses a risk because in a central manager failure, the whole system is put at risk yet this risk is mitigated by high-availability setups.
- Scalability Limitations: The model can be a bottleneck at a very high scale.
- The Peer-to-peer (P2P) Network Model.
- This method is more decentralized, and is usually used in research grids or volunteer computing projects like SETI at home.
The Peer-to-Peer (P2P) Network Model
Structure: There is no central master, however, all the nodes are peers having equal powers. Nodes are used to communicate directly to find resources and negotiate workload.
Pros:
- Scalability High Scalability: New nodes can be added without the requirement to reconfigure a central server.
- Resilience: The breakdown of just one node has a small impact on the overall network.
- Cost-Effectiveness: It is less complex to program with heterogeneous geographically distributed resources.
Cons:
- Low Efficiency: With no global perspective, there will be sub-optimal scheduling decisions that will lead to the reduced overall utilisation.
- Complex Coordination: The enforcement of global policies and provision of strong guarantees makes it more difficult.
- Security Issues: A decentralized open network is more challenging to secure.
Which Model Wins?
For the commercial cloud, where predictability, security, and efficiency are paramount, the centralized shared cluster model is the clear winner. The P2P model’s strengths, however, make it relevant for edge computing, blockchain networks, and specific distributed computing applications.
The Modern Context – Containers and Kubernetes
Virtual machines are no longer the topic of discussion topic. These concepts have been improved by the introduction of containers and Kubernetes.
Containers vs. virtual machines Containers are lighter, where they share the host operating-system kernel instead of implementing a full hardware stack. This has the effect of reducing startup time and density, and more containers can be operated on the same hardware than on a virtual machine.
Kubernetes as the cluster operating system: Kubernetes is slightly more or less like an operating system of a virtual cluster. It is not sensitive to the type of underlying nodes, whether it is physical servers, virtual machines on a cloud, or a combination of both. It automates:
- Deployment and scaling: It automatically deploys and removes containerized applications.
- Load balancing: It distributes the traffic between the healthy containers.
- Container live migration on node failures: In this case, a node falls and the Kubernetes re-scheduling and reroutes the already running containers on that node to a healthy node, performing a recovery-driven migration.
The resource-management concepts, such as scheduling, isolation, load balancing, also do not change; Kubernetes implements them in a container-native way, thus providing even higher agility and efficiency.
Conclusions: The Hidden Driver of Digital Transformation
Digital clusters and advanced resource management are not just theoretical topics; they are the basis of digital agility. They could help a start-up to get computing power, similar to that of a Fortune 500 company, without paying to use all the resources. They make global applications more robust, enabling them to expand on a global scale, as well as continuity in case of hardware problems.
The next time you watch a film without buffering, access a mobile application that commonly responds to input in real-time, or a chatbot-based AI answers your query, remember the engine under the hood. It is a self-evolving virtual-cluster engine that self-refines under the direction of smart resource managers that do the magic of live migration silently and smoothly. It is based on this that raw computing becomes a utility as reliable and on-demand as electricity.
FAQs
What is Resource Management in Cloud Computing?
Resource management in cloud computing can be understood as the process of distributing, controlling and optimizing the resources including CPU, memory, storage and network bandwidth to be effectively utilized and used.
How Do Virtual Clusters Improve Resource Utilization in the Cloud?
Virtual Clusters enhance better utilization of resources in that the workloads are dynamically distributed within the virtual machines. This will ensure there is a balanced computation demand, wastage of resources is avoided, and cloud applications perform better.
What Techniques are Used for Resource Management in Cloud Computing?
Such common methods are resource provisioning, scheduling, load balancing, monitoring and auto-scaling. These procedures are used to efficiently distribute resources and ensure optimum functionality in the cloud.
Why are Virtual Clusters Important for Cloud Infrastructure?
Virtual Clusters enable organisations to scale workloads, environment isolation and better management of computing resources. They are flexible, scalable and enhance efficiency in the modern cloud infrastructure.
How does Virtualization Help in Resource Management in Cloud Computing?
Virtualization is abstracting physical machines and enables the use of more than one virtual machine on the server. This assists the cloud providers in dynamically assigning the CPU, memory and storage resources in line with the workload demand.
Can Virtual Clusters Support High-Performance Computing Workloads?
Yes, high-performance computing can be implemented using virtual clusters as the complex workload can be distributed to a number of virtual machines or nodes. It allows processing data faster and better computation.